Confiabilidad:
En cualquier sistema de bases de datos, centralizado o distribuido, se debe ofrecer garantías de que la información es confiable. Así cada consulta o actualización de la información se hace mediante transacciones, las cuales tiene un inicio y un fin. En sistemas distribuidos el manejo de la durabilidad de las transacciones es aun más complejo, ya que una sola transacción puede involucrar 2 o más sitios de la red. Entonces el control de recuperación en sistemas distribuidos debe asegurar que el conjunto de agentes que participan en una transacción realicen todo un compromiso (commit)) de que toso al mismo tiempo restablezcan la información anterior (roll-back).
domingo, 18 de noviembre de 2012
Investigar las disciplinas del Interbloqueo: prevención, detección, eliminación y recuperación.


Fuentes de informacion: http://es.scribd.com/doc/40120259/DISENO-DE-BDD-copia
Algoritmos de Control de Concurrencia
Basados en Bloqueos
Basados en estampas de tiempo


Pruebas de validación optimistas



Fuentes: http://es.scribd.com/doc/80796514/Ensayo-Base-de-Datos-Distribuidos-Leonel
En los algoritmos basados en candados, las
transacciones indican sus intenciones solicitando candados al despachador
(llamado el administrador de candados). Los candados son
de lectura (rl), también llamados compartidos, o de escritura (wl),
también llamados exclusivos. Como se aprecia en la tabla siguiente, los
candados de lectura presentan conflictos con los candados de escritura, dado
que las operaciones de lectura y escritura son incompatibles.
|
|
rl
|
wl
|
|
rl
|
Si
|
No
|
|
Wl
|
No
|
No
|
En sistemas basados en candados, el despachador es un administrador
de candados (LM). El administrador de transacciones le pasa al
administrador de candados la operación sobre la base de datos (lectura o
escritura) e información asociada, como por ejemplo el elemento de datos
que es accesado y el identificador de la transacción que está enviando la
operación a la base de datos. El administrador de candados verifica si el
elemento de datos que se quiere accesar ya ha sido bloqueado por un candado. Si
candado solicitado es incompatible con el candado con que el dato está
bloqueado, entonces, la transacción solicitante es retrasada. De otra forma, el
candado se define sobre el dato en el modo deseado y la operación a la base de
datos es transferida al procesador de datos. El administrador de transacciones
es informado luego sobre el resultado de la operación. La terminación de una
transacción libera todos los candados y se puede iniciar otra transacción
que estaba esperando el acceso al mismo dato.
Basados en estampas de tiempo
A diferencia de los algoritmos basados en candados, los
algoritmos basados en estampas de tiempo no pretenden mantener la seriabilidad
por exclusión mutua. En lugar de eso, ellos seleccionan un orden de
serialización a priori y ejecutan las transacciones de acuerdo a ellas. Para
establecer este ordenamiento, el administrador de transacciones le asigna a
cada transacción Ti una estampa de tiempo única ts (Ti ) cuando
ésta inicia. Una estampa de tiempo es un identificador simple que
sirve para identificar cada transacción de manera única. Otra propiedad de las
estampas de tiempo es la monoticidad , esto es, dos estampas de tiempo
generadas por el mismo administrador de transacciones deben ser monotonicamente
crecientes. Así, las estampas de tiempo son valores derivados de un dominio
totalmente ordenado.
Existen varias formas en que las estampas de tiempo se
pueden asignar. Un método es usar un contador global monotonicamente creciente.
Sin embargo, el mantenimiento de contadores globales es un problema en sistemas
distribuidos. Por lo tanto, es preferible que cada nodo asigne de manera autónoma
las estampas de tiempos basándose en un contador local. Para obtener la
unicidad, cada nodo le agrega al contador su propio identificador. Así, la
estampa de tiempo es un par de la forma
<contador local ,identificador de nodo >
Note que el identificador de nodo se agrega en la posición
menos significativa, de manera que, éste sirve solo en el caso en que dos nodos
diferentes le asignen el mismo contador local a dos transacciones diferentes.
El administrador de transacciones asigna también una estampa de tiempo a todas
las operaciones solicitadas por una transacción. Más aún, a cada elemento de
datos x se le asigna una estampa de tiempo de escritura, wts (x ),
y una estampa de tiempo de lectura ,rts (x ); sus valores
indican la estampa de tiempo más grande para cualquier lectura y escritura
de x , respectivamente.


Pruebas de validación optimistas



Fuentes: http://es.scribd.com/doc/80796514/Ensayo-Base-de-Datos-Distribuidos-Leonel
Actividad
Responda lo siguiente:
¿Que es álgebra relacional?
El álgebra relacional es un conjunto de operaciones que describen paso a paso como computar una respuesta sobre las relaciones, tal y como éstas son definidas en el modelo relacional.
Describe el aspecto de la manipulación de datos. Estas operaciones se usan como una representación intermedia de una consulta a una base de datos y, debido a sus propiedades algebraicas, sirven para obtener una versión más optimizada y eficiente de dicha consulta.
¿Como se aplica el algebra relacional a la optimizacion de consultas en Mysql?
¿Como se representa la proyección y la selección relacionado con las consultas a bases de datos?
¿Para que nos sirve la división (hablando de álgebra relacional) en las consultas?
presente 2 ejemplos que incluyan la utilización de el álgebra relacional
Estas operaciones son fundamentales en el sentido en que (1) todas las demás operaciones pueden ser expresadas como una combinación de éstas y (2) ninguna de estas operaciones pueden ser omitidas sin que con ello se pierda información.
Una reunión theta ( θ-Join) de dos relaciones es equivalente a:
Fuente de información : http://es.wikipedia.org/wiki/%C3%81lgebra_relacional#Proyecci.C3.B3n_.28.CE.A0.29
RESUELVA:



¿Que es álgebra relacional?
El álgebra relacional es un conjunto de operaciones que describen paso a paso como computar una respuesta sobre las relaciones, tal y como éstas son definidas en el modelo relacional.
Describe el aspecto de la manipulación de datos. Estas operaciones se usan como una representación intermedia de una consulta a una base de datos y, debido a sus propiedades algebraicas, sirven para obtener una versión más optimizada y eficiente de dicha consulta.
¿Como se aplica el algebra relacional a la optimizacion de consultas en Mysql?
¿Como se representa la proyección y la selección relacionado con las consultas a bases de datos?
¿Para que nos sirve la división (hablando de álgebra relacional) en las consultas?
presente 2 ejemplos que incluyan la utilización de el álgebra relacional
Las operaciones
Básicas
Cada operador del álgebra acepta una o dos relaciones y retorna una relación como resultado. σ y Π son operadores unarios, el resto de los operadores son binarios. Las operaciones básicas del álgebra relacional son:
Seleccióna (σ)
Permite seleccionar un subconjunto de tuplas de una relación (R), todas aquellas que cumplan la(s) condición(es) P, esto es:

Ejemplo:

Selecciona todas las tuplas que contengan Gómez como apellido en la relación Alumnos.
Una condición puede ser una combinación booleana, donde se pueden usar operadores como:  ,
, 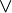 , combinándolos con operadores
, combinándolos con operadores  .
.
, , combinándolos con operadores .
Proyección (Π)
Permite extraer columnas (atributos) de una relación, dando como resultado un subconjunto vertical de atributos de la relación, esto es:

donde  son atributos de la relación R .
son atributos de la relación R .
son atributos de la relación R .
Ejemplo:

Selecciona los atributos Apellido, Semestre y NumeroControl de la relación Alumnos, mostrados como un subconjunto de la relación Alumnos
Producto cartesiano (x)
El producto cartesiano de dos relaciones se escribe como:

y entrega una relación, cuyo esquema corresponde a una combinación de todas las tuplas de R con cada una de las tuplas de S, y sus atributos corresponden a los de Rseguidos por los de S.
Ejemplo:
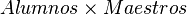
Muestra una nueva relación, cuyo esquema contiene cada una de las tuplas de la relación Alumnos junto con las tuplas de la relación Maestros, mostrando primero los atributos de la relación Alumnos seguidos por las tuplas de la relación Maestros.
Unión (∪)
La operación

retorna el conjunto de tuplas que están en R, o en S, o en ambas. R y S deben ser uniones compatibles.
Diferencia (-)
La diferencia de dos relaciones, R y S denotada por:
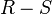
entrega todas aquellas tuplas que están en R, pero no en S. R y S deben ser uniones compatibles.
Estas operaciones son fundamentales en el sentido en que (1) todas las demás operaciones pueden ser expresadas como una combinación de éstas y (2) ninguna de estas operaciones pueden ser omitidas sin que con ello se pierda información.
No básicas o Derivadas
Entre los operadores no básicos tenemos:
Intersección (∩)
La intersección de dos relaciones se puede especificar en función de otros operadores básicos:

La intersección, como en Teoría de conjuntos, corresponde al conjunto de todas las tuplas que están en R y en S, siendo R y S uniones compatibles.
Unión natural (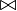 ) (Natural Join)
) (Natural Join)
) (Natural Join)
La operación unión natural en el álgebra relacional es la que permite reconstruir las tablas originales previas al proceso de normalización. Consiste en combinar las proyección, selección y producto cartesiano en una sola operación, donde la condición  es la igualdad Clave Primaria = Clave Externa (o Foranea), y la proyección elimina la columna duplicada (clave externa).
es la igualdad Clave Primaria = Clave Externa (o Foranea), y la proyección elimina la columna duplicada (clave externa).
es la igualdad Clave Primaria = Clave Externa (o Foranea), y la proyección elimina la columna duplicada (clave externa).
Expresada en las operaciones básicas, queda
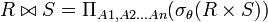
Una reunión theta ( θ-Join) de dos relaciones es equivalente a:

donde la condición es libre.
es libre.
Si la condición es una igualdad se denomina EquiJoin.
es una igualdad se denomina EquiJoin.
División (/)
Supongamos que tenemos dos relaciones A(x, y) y B(y) donde el dominio de y en A y B, es el mismo.
El operador división A / B retorna todos los distintos valores de x tales que para todo valor y en B existe una tupla  en A.
en A.
en A.
Agrupación (Ģ)
Permite agrupar conjuntos de valores en función de un campo determinado y hacer operaciones con otros campos.
Por ejemplo: Ģ sum(puntos) as Total Equipo (PARTIDOS).
Fuente de información : http://es.wikipedia.org/wiki/%C3%81lgebra_relacional#Proyecci.C3.B3n_.28.CE.A0.29
RESUELVA:
[2] Π código , descripción
(σ código= descripción P)
[3] Π nombre C, U , Π Id
Venta V (σ cantidad >500 V)
[4] Π nombre C
- V
[5] Π nombre C = V
[6] Π Id Venta (cantidad > cantidad(Id Venta =18)V)
[7] Π P – (σ población = “Palencia” C)
[8] Π P(V=(σ población = “Palencia, Valladolid” C ))
miércoles, 7 de noviembre de 2012
Cierre unidad III
Álgebra relacional aplicada a bases de datos distribuidas ( definición y ejemplos)
Definir fragmentos verticales se hace a través del operador de proyección del álgebra relacional operando sobre una relación global.

Analizar
Heurísticas
Es un algoritmo que abandona uno o ambos objetivos; por ejemplo, normalmente encuentran buenas soluciones, aunque no hay pruebas de que la solución no pueda ser arbitrariamente errónea en algunos casos; o se ejecuta razonablemente rápido, aunque no existe tampoco prueba de que siempre será así. Las heurísticas generalmente son usadas cuando no existe una solución óptima bajo las restricciones dadas (tiempo, espacio, etc.), o cuando no existe del todo.
Acceso concurrente
Un sistema que permite a varias estaciones de trabajo modificar en forma simultánea una misma base de datos.
Fuentes de información:
http://isisabcd.pbworks.com/w/page/33368354/Acceso%20concurrente%20a%20bases%20de%20datos
http://es.wikipedia.org/wiki/Heur%C3%ADstica_(inform%C3%A1tica)
http://definicion.dictionarist.com/parsing
http://www.carlosproal.com/bda/bda05.html
jueves, 1 de noviembre de 2012
Optimización de consultas distribuidas
Optimización de consultas distribuidas
El objetivo del procesamiento
de consultas en un ambiente distribuido es transformar una consulta sobre
una base de datos distribuida en una especificación de alto nivel a una estrategia de ejecución eficiente
expresada en un lenguaje de bajo nivel sobre bases de datos locales.
El problema de optimización de consultas es minimizar una
función de costo tal que función de costo total = costo de I/O + costo de CPU +costo
de comunicación.
Por ejemplo:
En las redes de área amplia (WAN), normalmente el costo de comunicación domina dado que hay una velocidad de comunicación relativamente
baja, los canales están saturados y el trabajo adición al requerido por los
protocolos de comunicación es considerable.
Así, los algoritmos diseñados para trabajar en una WAN, por
lo general, ignoran los costos de CPU y de I/O. En redes de área local (LAN) el
costo de comunicación no es tan dominante, así que se consideran los tres factores
con pesos variables.
Optimización global de consultas
Dada una consulta algebraica sobre fragmentos, el objetivo de
esta capa es hallar una estrategia de ejecución para la consulta cercana a la
óptima.
La estrategia de ejecución para una consulta distribuida puede ser descrita
con los operadores del álgebra relacional y con primitivas de comunicación para
transferir datos entre nodos.
Un aspecto importante de la optimización de consultas es el ordenamiento de juntas, dado que algunas permutaciones de juntas dentro de la consulta pueden
conducir a un mejoramiento de varios órdenes de
magnitud.
La salida de la capa de optimización global es una consulta
algebraica optimizada con operación de comunicación incluida sobre los
fragmentos.
Optimización local de consultas
El trabajo de la última capa se efectúa en todos los nodos con fragmentos
involucrados en la consulta. Cada consulta que se ejecuta en un nodo,
llamada consulta local, es optimizada usando el esquema local del nodo. Hasta
este momento, se eligen los algoritmos para realizar las operaciones
relacionales. La optimización local utiliza los algoritmos de sistemas
centralizados.
Fuente de informacion: http://es.scribd.com/doc/44436671/Unidad-III
jueves, 25 de octubre de 2012
Estrategias de procesamiento de consultas distribuidas
Las consultas distribuidas
detienen acceso a datos de varios orígenes de datos heterogéneos. Estos orígenes de datos pueden estar
almacenados en el mismo equipo o en equipos diferentes.
El procesamiento de consultas tiene
varias etapas a seguir para resolver una consulta SQL, las características del
modelo relacional permiten quecada motor de base de datos elija su propia representación que,comúnmente,
resulta ser el álgebra relacional .Existen
varios medios para calcular la respuesta a una consulta. En el caso del sistema centralizado, el criterio principal
para determinar el costo de una estrategia específica es el número de
acceso al disco. En un sistema distribuido es preciso tener en cuenta otros
factores como son:
•El costo de transmisión de datos en la
red.
•Repetición y fragmentación.
•Procesamiento de intersección simple.
Arboles de consultas
Pasos
– Parsing y
traducción de la consulta
– Optimización
– Generación de código
– Ejecución de
la consulta

Transformaciones equivalentes
Cuando una base de datos se encuentra en múltiples servidores ydistribuye a un número determinado de nodos tenemos:
•El servidor recibe una petición de un
nodo.
•El
servidor es atacado por el acceso concurrente a la base de datos cargada
localmente.
•El servidor muestra un resultado y le
da un hilo a cada una de las maquinas nodo
de la red local.
Cuando una base de datos es acezada de
esta manera la técnica que se utiliza es la de fragmentación de datos que puede
ser hibrida, horizontal y vertical.
En esta
fragmentación lo que no se quiere es perder la consistencia delos datos, por lo
tanto se respetan las formas normales de la base de datos.
Bueno para realizar una transformación en la consulta primero desfragmentamos siguiendo los estándares marcados por las reglas formales y
posteriormente realizamos el envió y la maquina que recibe es la que muestra el resultado pertinente para el
usuario, de esta se puede producir una copia que será la equivalente
a la original.
Métodos de ejecución del join
Existen diferentes algoritmos que pueden obtener
transformacioneseficientes en el procesamiento de consultas.
Join en bucles (ciclos) anidados
Si z = r s, r recibirá el nombre de relación
externa y s se llamará relación interna, el algoritmo de bucles anidados se
puede presentar como sigue:
Para cada tupla tr en s si (tr,ts) si satisface la
condición, entonces añadir tr * ts al resultado Donde tr * ts será la
concatenación de las tuplas tr y ts. Como para cada registro de r se tiene que
realizar una exploración completa de ts, y suponiendo el peor caso, en el cual
la memoria intermedia sólo puede concatenar un bloque de cada relación,
entonces el número de bloques a acceder es de sr bn b. Por otro lado, en el
mejor de los casos si se pueden contener ambas relaciones en la memoria
intermedia entonces sólo se necesitarían accesos a bloques.
Join en bucles anidados por bloques
Una variante del algoritmo anterior puede lograr un
ahorro en el acceso a bloques, si se procesan las relaciones por bloques en vez
de por tuplas. Para cada bloque Br dar a igual para cada bloque Bs de s, para
cada tupla tr en Br.
La diferencia principal en costos de este algoritmo
con el anterior es que en el peor de los casos cada bloque de la relación
interna s se lee una vez por cada bloque de dr y no por cada tupla de la
relación externa.
Join por mezcla
Este algoritmo se puede utilizar para calcular si
un Join natural es óptimo en la búsqueda o consulta. Para tales efectos, ambas
relaciones deben estar ordenadas para los atributos en común es decir se asocia
un puntero a cada relación, al principio estos punteros apuntan al inicio de cada
una de las relaciones. Según avance el algoritmo el puntero se mueve a través
de la relación. De este modo se leen en memoria un grupo de tuplas de una
relación con el mismo valor en los atributos de las relaciones.
¿Qué se debe de tomar en cuenta en este algoritmo?
•Se tiene que ordenar primero, para después
utilizar este método.
•Se tiene que considerar el costo de ordenarlo /
las relaciones.
•Es más fácil utilizar pequeñas tuplas.
Join por asociación.
Al igual que el algoritmo de join por mezcla, el
algoritmo de join por asociación se puede utilizar para un Join natural o un
equi-join. Este algoritmo utiliza una función de asociación h para dividir las
tuplas de ambas relaciones. La idea fundamental es dividir las tuplas de cada relación
en conjuntos con el mismo valor de la función de asociación en los atributos de
join.
El número de bloques ocupados por las particiones
podría ser ligeramente mayor que.
Debido a que los bloques no están completamente
llenos. El acceso a estos bloques puede añadir un gasto adicional de 2·max a lo
sumo, ya que cada una de las particiones podría tener un bloque parcialmente ocupado
que se tiene que leer y escribir de nuevo.
Join por asociación híbrida
El algoritmo de join por asociación híbrida realiza
otra optimización; es útil cuando el tamaño de la memoria es relativamente
grande paro aún así, no cabe toda la relación s en memoria. Dado que el
algoritmo de join por asociación necesita max +1 bloques de memoria para dividir
ambas relaciones se puede utilizar el resto de la memoria (M – max – 1
bloques)para guardar en la memoria intermedia la primera partición de la relación
s, esto es, así no es necesaria leerla ni escribirla nuevamente y se puede
construir un índice asociativo.
Cuando r se divide, las tuplas de tampoco se
escriben en disco; en su lugar, según se van generando, el sistema las utiliza
para examinar el índice asociativo en y así generar las tuplas de salida del
join. Después de utilizarlas, estas tuplas se descartan, así que la partición
no ocupa espacio en memoria. De este modo se ahorra un acceso de lectura y uno de
escritura para cada bloque de y.
Join Complejos
Los join en bucle anidado y en bucle anidado por
bloques son útiles siempre, sin embargo, las otras técnicas de join son más
eficientes que estas, pero sólo se pueden utilizar en condiciones particulares
tales como join natural o equi-join. Se pueden implementar join con condiciones
más complejas tales como conjunción o disyunción Dado un join de las forma se
pueden aplicar una o más de las técnicas de join descritas anteriormente en
cada condición individual, el resultado total consiste en las tuplas del
resultado intermedio que satisfacen el resto de las condiciones. Estas
condiciones se pueden ir comprobado según se generen las tuplas. La
implementación de la disyunción es homóloga a la conjunción.
Outer
Join (Join externos)
Un outer join es una extensión del operador join
que se utiliza a menudo para trabajar con la información que falta.
Por
ejemplo:
Suponiendo que se desea generar una lista con todos
los choferes y los autos que manejan (si manejan alguno) entonces se debe
cruzar la relación Chofer con la relación Móvil. Si se efectúa un join
corriente se perderán todas aquellas tuplas que pertenecen a los choferes, en
cambio con un outer join se pueden desplegar las tuplas resultado incluyendo a aquellos
choferes que no tengan a cargo un auto.
El outer
join tiene tres formas distintas: por la izquierda, por la derecha y completo.
El join por la izquierda ( ) toma todas las tuplas de la relación de la
izquierda que no coincidan con ninguna tupla de la relación de la derecha, las
rellena con valores nulos en los demás atributos de la relación de la derecha y
las añade al resultado del join natural.
Un outer join por la derecha ( ) es análogo al
procedimiento anterior y el outer join completo es aquel que efectúa ambas
operaciones.
Para el caso
de un outer join completo se puede calcular mediante extensiones de los
algoritmos de join por mezcla y join por asociación.
Fuente de informacion: http://es.scribd.com/doc/44436671/Unidad-III
lunes, 8 de octubre de 2012






sábado, 29 de septiembre de 2012
Ejemplos de fragmentación
Fragmentacion Horizontal
Alumnos
Nc Nom Dir Tel Edad Cve_Car Cve_Tec PP PA Sem
1.- Realice una fragmentación de los alumnos menores de edad.
a1= SL edad<18 (alumnos)
a2= SL edad>=18 (alumnos)
Reconstrucción:
Alumnos= a1 u a2
2.- Realice una fragmentación de los alumnos que se encuentran en los semestres 2 al 6 y que tengan promedio aritmético =100.
a1= SL (sem>=2 and sem<=6 ) and pa=100 (alumnos)
a2= SL (sem<2 or sem>6) or pa<>100 (alumnos)
Reconstrucción:
Alumnos= a1 u a2
3.- Realice una fragmentación de los alumnos menores de edad con clave de carrera=105 y otro fragmento que tenga a los alumnos entre 18 y 20 años de edad con clave de carrera=104.
a1= SL edad<18 and cve_tec=105 (alumnos)
a2= SL (edad>=18 and edad<=20 ) and cve_tec=104 (alumnos)
a3= SL edad>18 and cve_tec=105(alumnos)
a4= SL (edad<18 or edad>20) and cve_tec=104(alumnos)
a5= SL cve_tec <> 105 and cve_tec<> 104 (alumnos)
Fuente de información :http://base-de-datos0.tripod.com/unidad_3.htm
Fragmentacion Vertical
Cve_pac Nom Dir Edad TS Sala Cve_diag Cve_trat Cve_dr Status
1.-Realice una fragmentación de la tabla de pacientes por sus datos personales.
p1= PJ cve_pac, nom, dir, edad (pacientes)
p2= PJ cve_pac, ts, sala, cve_diag, cve_trat, Cve_dr, Status (pacientes)
Reconstrucción:
Pacientes= p1 jn cve_pac=cve_pac p2
2.- Realice una fragmentación por nombre, clave del diagnostico, clave del tratamiento y clave del doctor y otra por tipo de sangre.
p1= PJ cve_pac, nom, cve_diag, cve_trat, cve_dr (pacientes)
p2=PJ cve_pac, ts (pacientes)
p3= PJ cve_pac, dir, edad, sala, status (pacientes)
Reconstrucción:
Pacientes= (p1 u p2) jn cve_pac=cve_pac p3
3.- Realice una fragmentación por nombre, edad, tipo de sangre y otra por cve_diag, cve_trat y status, considere otro fragmento por nom, cve_pac y status de la tabla de pacientes.
p1=PJ cve_pac, nom, ts (pacientes)
p2= PJ cve_pac, cve_diag, cve_trat, status (pacientes)
p3= PJ cve_pac, dir, sala, cve_dr (pacientes)
Reconstrucción:
Pacientes= (p1 u p2) jn cve_pac=cve_pac p3
** El ultimo fragmento no se puede realizar ya que el campo nombre y status ya se encuentra en el fragmento p1.
Fragmentacion Hibrida
Considere la relación global
EMP( empnum, name, sal, tax, mrgnum, depnum )
Las siguientes son para obtener una fragmentación mixta, aplicando la vertical seguida de la horizontal:
EMP1 = SL depnum <= 10 PJempnum, name, mgrnum, depnum EMP
EMP2 = SL 10 < depnum <= 20 PJempnum, name, mgrnum, depnum EMP
EMP3 = SL depnum > 20 PJempnum, name, mgrnum, depnum EMP
EMP4 = PJ empnum, name, sal, tax EMP
La reconstrucción de la relación EMP es definida por la siguiente expresión:
EMP = UN(EMP1, EMP2, EMP3)JNempnum = empnumPJempnum, sal, tax EMP4
Finalmente, como otro ejemplo considere el siguiente esquema global
EMP(EMPNUM, NAME, SAL, TAX, MGRNUM, DEPNUM)
DEP(DEPNUM, NAME, AREA, MGRNUM)
SUPPLIER(SNUM, NAME, CITY)
SUPPLY(SNUM, PNUM, DEPNUM, QUAN)
Después de aplicar una fragmentación mixta se obtiene el siguiente esquema fragmentado
EMP1 = Sldepnum <= 10 PJempnum, name, mgrnum, depnum (EMP)
EMP2 = SL 10 < depnum <= 20 PJempnum, name, mgrnum, depnum (EMP)
EMP3 = SL depnum > 20 PJempnum, name, mgrnum, depnum (EMP)
EMP4 = PJ empnum, name, sal, tax (EMP)
DEP1 = SL depnum <= 10 (DEP)
DEP2 = SL 10 < depnum <= 20 (DEP)
DEP3 = SL depnum > 20 (DEP)
SUPPLIER1 = SL city == "SF" (SUPPLIER)
SUPPLIER2 = SL city == "LA" (SUPPLIER)
SUPPLY1 = SUPPLYSJsnum == snumSUPPLIER1
SUPPLY2 = SUPPLYSJsnum == snumSUPPLIER2
Fuente información: http://lasbasededatos.blogspot.mx/2006/09/fragmentacion-verticalhorizontal-y.html
Suscribirse a:
Entradas (Atom)